
뇌를 자극하는 윈도우즈 시스템 프로그래밍(저자, 윤성우)
01. 쓰레드란 무엇인가?
두 개 이상의 일을 동시에 처리하기 위해서 추가적으로 프로세스를 생성하는 것은 막대한 컨텍스트 스위칭Context Switching으로 이어져 성능에 영향을 미치기 때문에 부담스러운 일이다.
▶ 다시, 컨텍스트 스위칭
: 컨텍스트 스위칭Context Switching은 프로세스의 상태 정보를 복원하고 저장하는 과정이다. 호출 횟수는 상황과 시스템에 따라서 변동이 있으나, 초당 수십 회 이상 발생하므로 성능 저하의 원인이 된다.
그렇다면, 컨텍스트 정보의 개수를 줄이는 방법으로 성능 저하를 어느 정도 해결할 수 있다. 컨텍스트 정보는 프로세스의 상태 정보와 관련이 있으므로, 결국 프로세스 상태 정보를 줄여야 한다는 것이다.
컨텍스트 스위칭은 프로세스들이 완전히 서로 독립된 상태에 놓여 있기 때문에 필요로 하는 것인데, A 프로세스와 B 프로세스가 완전히 별개가 아닌, 어느 정도 공유된 상태라면 성능 저하를 줄일 수 있지 않을까 하는 생각으로 탄생된 것이 쓰레드다.
01. A. 쓰레드
쓰레드와 프로세스는 서로 비슷하지만, 차이점이 있다. 가장 큰 차이는 서로가 서로에게 독립되는지 여부다. 프로세스는 완전히 독립된 두 개의 프로그램 실행을 위해서 사용이 되고, 쓰레드는 하나의 프로그램에서 둘 이상의 프로그램 흐름을 만들기 위해서 디자인된 것이다.
프로세스와 다르게 쓰레드는 서로 공유하는 상태 정보들이 있다. 이것이 쓰레드의 컨텍스트 스위칭을 빠르게 하는 요인이다. 위의 내용을 정리하면 다음과 같다.
▶ 쓰레드와 프로세스의 비교
1. 쓰레드는 하나의 프로그램 내에서 여러 개의 실행 흐름을 두기 위한 모델이다.
2. 쓰레드는 프로세스처럼 완전히 독립된 구조가 아니며, 쓰레드 상호 간에 공유하는 요소가 있다.
3. 쓰레드는 공유 요소가 있기에 컨텍스트 스위칭에 걸리는 시간이 프로세스보다 짧다.
01. B. 메모리 관점에서의 프로세스와 쓰레드
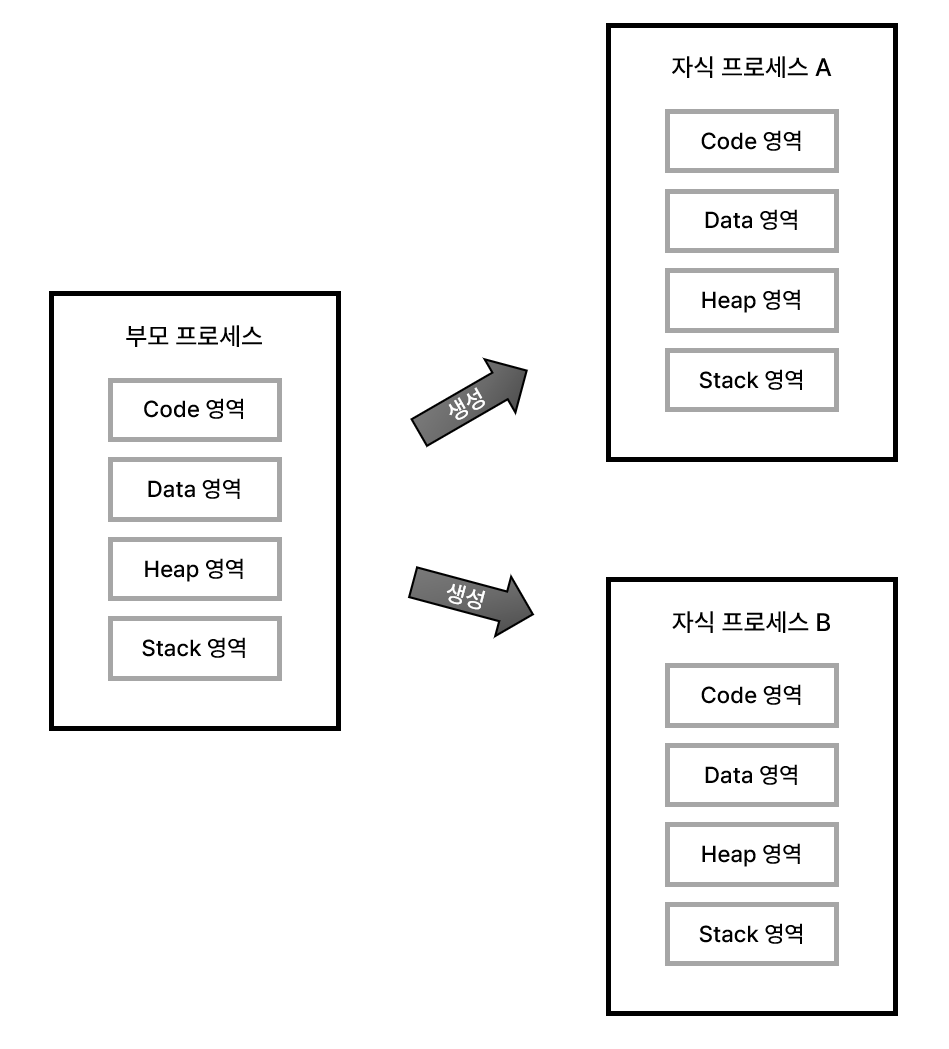
위 그림은 하나의 프로세스 내에서 두 개의 자식 프로세스를 생성했을 시, 메모리 구조를 나타낸다. 자식 프로세스는 생성 이후, 모든 것이 부모 프로세스와 독립적이다. 부모 프로세스는 자신이 가지고 있던 핸들 테이블을 상속하지만, 이는 생성 과정에 발생하는 일이며 메모리 구조 상으로는 생성 이후에 어떤 관계도 없다.

위 그림은 이전의 그림과 다르게 프로세스 대신에 쓰레드를 생성했을 경우 메모리 구조를 나타낸다. 그림을 통해서 쓰레드 생성 시에는 해당 쓰레드만을 위한 Stack을 생성할 뿐, 이외의 영역은 부모 프로세스 영역을 공유하고 있다. 이를 통해 쓰레드 특성 몇 가지를 살펴보자.
쓰레드는 자식 프로세스가 아니므로, 부모 프로세스라는 명칭은 옳지 않다. 단지 설명을 위한 것
쓰레드 특성 1 : 쓰레드마다 스택을 독립적으로 할당한다.
스택은 함수 호출 시 전달되는 인자, 되돌아갈 주소값 및 함수 내에서 선언하는 변수 등을 저장하기 위한 메모리 공간이다. 간단하게 말해서는 함수 호출 시 필요한 메모리 영역인데, 쓰레드도 프로세스와 마찬가지로 독립적으로 스택을 할당하여 가진다.
이 메모리 영역이 독립적이라는 뜻은 추가적인 실행 흐름을 만들 수 있다는 의미가 된다. 달리 말하자면 실행 흐름의 추가를 위한 최소 조건이 독립된 스택의 제공이다.
쓰레드 특성 2 : 코드 영역을 공유한다.
프로세스는 독립 구조이기 때문에 프로세스 A에서 프로세스 B가 가지고 있는 함수를 호출하는 것은 불가능하다. 그렇지만 쓰레드는 자신을 생성한 프로세스가 가지고 있는 함수를 실행할 수 있다. 앞서 말했던 것처럼 Stack 영역을 제외하고는 공유하고 있기 때문이다.
쓰레드 특성 3 : 데이터 영역과 힙을 공유한다.
쓰레드 A가 접근 가능한 힙과 데이터 영역은 쓰레드 B도 접근할 수 있다. 따라서 힙과 데이터 영역에 메모리 공간을 할당하여 IPC와 같은 통신 기법이 없이 서로 통신하는 것이 가능하다. 조금 더 직관적으로 말하면 전역변수와 malloc 함수를 통해서 동적 할당된 메모리 공간은 공유가 가능하다.
01. C. Window에서의 프로세스와 쓰레드
쓰레드는 프로세스 내부에서 생성되는 것이라고 설명했다. 그렇다면 구체적인 프로세스와 쓰레드의 관계는 어떨까? 결론을 알리기 전에 먼저 앞서 공부한 프로세스 스케줄러를 생각해보자. 쓰레드도 CPU의 시간을 할당 받아서 실행되기 때문에 쓰레드 스케줄러의 존재도 추측할 수 있다.
내부 커널의 구현 원리에 따라서 나뉘는데, Windows의 관점에서 프로세스는 단순히 쓰레드를 담는 상자에 지나지 않는다. 실제 프로그램의 흐름을 형성하는 것은 쓰레드다. 앞서의 프로세스 스케줄러나 프로세스 상태 정보들은 전부 쓰레드다. 프로세스가 상태를 지니는 것이 아니라, 쓰레드가 상태를 가지는 것이고 스케줄러의 실행 단위로 잡는 기준도 프로세스가 아닌, 쓰레드다.
Windows에서 실행의 중심에 있는 것은 프로세스가 아닌, 쓰레드다.
▶ 컨텍스트 스위칭이 빨라진 쓰레드
: 쓰레드는 서로 영역 공유를 통해서 컨텍스트 스위칭이 빠르다고 말했었다. 쓰레드의 컨텍스트 스위칭은 어떠한 일이 벌어지기 때문에 이러한 결과를 도출할 수 있었을까? 시스템 디자인 과정에서 설계한 레지스터 sp, fp, pc는 프로세스 컨텍스트 스위칭의 경우라면 그 값들을 저장하고 복원해야 한다. 하지만 쓰레드라면?
pc는 실행해야 할 명령어가 있는 위치를 가리키다 보니, 이 레지스터 정보는 컨텍스트 스위칭 시에 지장을 받지 않는다고 생각하기 쉽다. 코드 영역을 공유하고 있다고 말했기 때문이다. 그러나 pc는 프로그램의 실행 흐름과 관련이 있다. 쓰레드별로 main 함수를 독립적으로 가지고 있고 함수의 호출도 독립적으로 진행되기 때문에 쓰레드별로 현재 pc가 가져야 하는 값은 다르다.
코드 영역 공유는 호출할 수 있는 함수들을 공유하는 것이지 pc 정보까지 공유하는 것이 아니다. 이 부분은 프로세스와 동일하게 흘러간다. 그러면 fp와 sp는 어떠한가? 역시 공유가 불가능하다. 스택은 쓰레드 별로 독립적인데 스택의 정보를 저장하는 곳에 사용되는 fp와 sp가 공유될 수 없다.
범용 사용이 가능한 레지스터들에 대해서 생각해 보자. 범용 레지스터들은 연산 결과를 저장하고나 메모리에 저장된 데이터를 이동시키거나 할 때 사용된다. 연산은 프로그램 흐름에 따라 진행되는 것이기에 공유가 어려운데, 가능성은 존재한다.
범용 레지스터의 개수가 많고 일부는 전역으로 선언된 변수를 위해 할당하기로 결정하였다면 쓰레드 컨텍스트 스위칭 시 전혀 영향을 받지 않을 것이다. 데이터 영역은 공유되기 때문이다. 그렇지만 이것도 시스템 디자인의 상태에 따라 달라지는 것이기 때문에 일반적인 상황으로 언급하기엔 부족하다.
그러면 어떠한 이유로 빨라지는 것일까?
레지스터에서만 답을 찾지 않고, 메모리 관리 측면에서 이야기를 풀어가보자. 캐쉬는 CPU에서 한 번 이상 읽은 메인 메모리의 데이터를 저장하고 있다가 CPU가 다시 그 메모리에 저장된 데이터를 요구할 때, 메인 메모리를 통하지 않고 바로 값을 전달해 주는 용도로 사용된다.
개념적으로 캐쉬는 CPU와 메인 메모리 사이에 존재한다. 이러한 캐쉬가 성능에 미치는 영향은 매우 높다. 캐쉬 메모리는 용량도 중요한데, 메모리를 운영하는 데 필요한 알고리즘도 중요하다. 용량이 큰데, 알고리즘이 잘못되어 매번 메인 메모리부터 데이터를 읽는다면 엄청난 성능 저하로 이어질 것이다.
컨텍스트 스위칭이 일어나면 캐쉬 또한, 새로운 기준으로 캐쉬 정보를 다시 올려야 한다. 프로세스 사이에는 공유되는 메모리가 하나도 없기 때문에 이전에 저장되었던 0x3000번지의 데이터를 요구한다고 해도 다시 메인 메모리로부터 가져와서 전달해야 하기 때문이다. 이러한 점이 프로세스 컨텍스트 스위칭에 부담이 되는 요소 중 하나이다.
반면에 쓰레드라면 캐쉬를 비우지 않아도 된다. A 쓰레드가 원하는 0x13000번지의 데이터는 B 쓰레드가 원하는 0x13000번지의 데이터와 동일하기 때문이다. 이러한 차이로 인해서 컨텍스트 스위칭이 빨라진다.
▶ 달라지는 것은 없다
: 실행 단위가 쓰레드라고 해도 달라지는 것은 없다. 적용되는 대상이 프로세스가 아니라 쓰레드가 되었을 뿐이다.
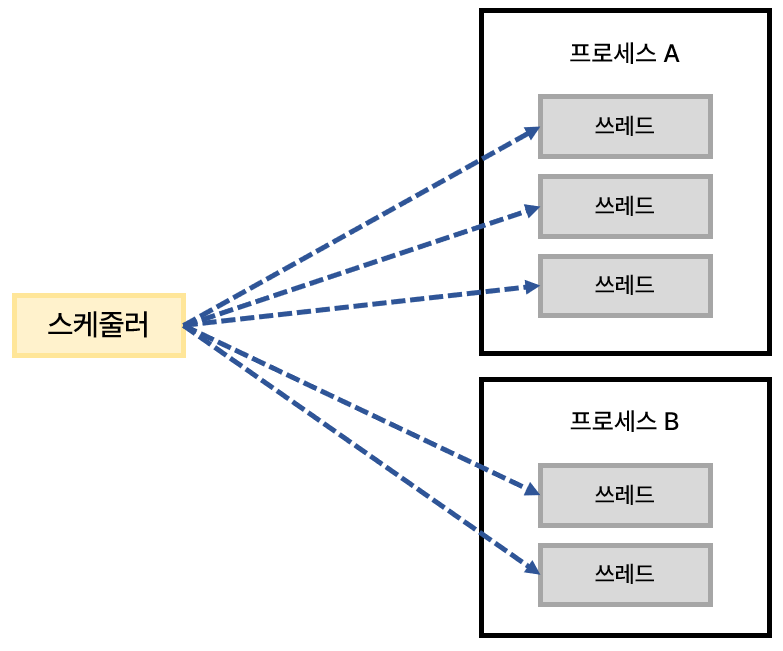
프로세스 컨텍스트 스위칭은 존재하지 않을까? 위 그림에서 프로세스 B 안에는 두 개의 쓰레드가 존재한다. 이 둘은 하나의 프로세스 내에서 존재하므로 별개의 프로세스가 아니다. 그러나 프로세스 A의 쓰레드가 실행되는 도중에 프로세스 B의 쓰레드로 이동하면서 발생한 컨텍스트 스위칭은 프로세스 컨텍스트 스위칭과 다를 바 없다. 서로 다른 프로세스에 존재하는 쓰레드 간 이동이기 때문이다.
▶ 쓰레드가 없는 프로세스는 존재하지 않는다.
: 참고로 쓰레드가 없는 프로세스는 존재할 수 없다. Hello World!를 출력하는 단순한 프로그램도 프로세스 생성과 동시에 main 함수를 호출해 줄 쓰레드를 생성하기 때문이다. 이러한 쓰레드를 가리켜 main 쓰레드라고 부른다.
02. 쓰레드 구현 모델에 따른 구분
앞선 이야기가 쓰레드의 특성이었다면 이번에는 쓰레드의 구현 원리에 대해서 알아보자. 쓰레드는 누구에 의해서 만들어질까?
02. A. 커널 레벨Kernel Level 쓰레드와 유저 레벨User Level 쓰레드
첫 번째 경우로 쓰레드의 생성 주체는 커널일 수 있다. 이러한 경우에는 운영체제가 제공하는 시스템 함수 호출을 통해서 쓰레드 생성을 요구해야 한다. 그러면 운영체제는 해당 쓰레드를 생성 및 관리하며 새로운 흐름을 형성하도록 도와준다.
프로그래머 요청에 따라 쓰레드를 생성 및 스케줄링하는 주체가 커널인 경우, 이를 가리켜 커널 레벨Kernel Level 쓰레드라고 한다. 커널 레벨에서 쓰레드가 지원된다는 뜻이다.
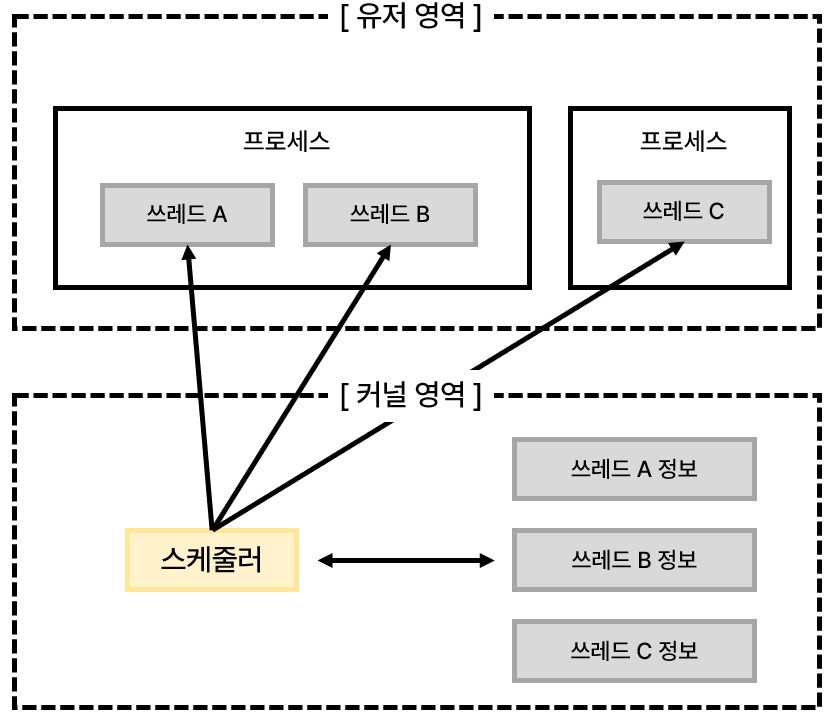
위 그림은 커널 레벨 쓰레드의 특성을 보여준다. 그림에 있는 유저 영역은 사용자에 의해서 할당되는 메모리 공간을 의미한다. 하나의 프로세스에 할당되는 메모리 공간이 4GB라고 가정해 보자. 그러면 일부 영역은 프로그램 코드를 올리는데 사용되고, 또 일부는 실행하는 과정에서 변수 선언이나 메모리의 동적 할당 등의 용도로 사용된다.
이렇게 프로그램이 동작하기 위해 사용되는 메모리 공간을 가리켜 유저 영역이라고 한다. 간략하게 설명하면 코드 영역, 데이터 영역, 스택 및 힙 영역을 가리켜 유저 영역이라고 한다.
그리고 그림에 유저 영역과 같이 있는 커널 영역은 무엇일까? 하나의 프로세스에게 할당된 총 메모리 공간 중에서 유저 영역을 제외한 나머지 영역을 커널 영역이라고 한다. 운영체제가 실행되기 위해서 운영체제 역시 메모리에 올라가야 하고, 또 일반 프로그램처럼 실행되는 과정에서 변수 선언도 하고 메모리를 동적 할당하기도 한다.
이렇게 운영체제에서 하나의 소프트웨어를 실행하기 위해서 필요한 메모리 공간을 커널 영역이라 한다.
두 영역이 분리되지 않으면 프로그램을 실행시키기 위해서 필요한 메모리 공간과 운영체제의 실행을 위한 메모리 공간을 관리하는 측면에서 엄청난 곤란을 겪을 수 있다. 과거 32비트 Windows 운영체제에서는 4GB 메모리 영역 중에서 2GB는 유저 영역으로, 나머지 2GB를 커널 영역으로 활용하였다.
오늘날 64비트 운영체제에서는 총 16TB의 메모리를 유저 영역과 커널 영역으로 각각 8TB씩 할당하고 있다. 다시 본론으로 돌아와서 위 그림을 살펴보자.
쓰레드에게 일을 시키기 위한 코드는 프로그래머가 개발하므로 쓰레드 A, B, C의 실행코드는 유저 영역에 존재할 것이다. 그러나 스케줄러와 쓰레드 정보는 커널 영역에 존재한다. 이것이 바로 커널 레벨 쓰레드의 유형이다. 오늘날 대부분의 운영체제는 커널 레벨 쓰레드를 기반으로 쓰레드 모델을 지원한다.
두 번째 경우로, 유저 레벨 쓰레드 모델이 있다. 멀티 프로세스 운영체제라고 해서 커널이 기본적으로 쓰레드를 지원하는 것은 아니다. 과거 UNIX의 경우엔 멀티 프로세스 운영체제 였으나 쓰레드를 지원하지 않았다.
커널에서 쓰레드 기능을 지원하지 않을 때 생각할 수 있는 것이 유저 레벨 쓰레드다. 커널이 쓰레드 모델을 제공하지 않을 경우, 커널에 의존적이지 않은 형태로 쓰레드의 기능을 제공하는 라이브러리를 활용할 수 있는데, 이러한 방식으로 제공되는 것을 유저 레벨 쓰레드라 한다.
유저 레벨 쓰레드와 커널 레벨 쓰레드는 기능 제공 주체가 누구냐에 달려 있다.
▶ 커널 영역
: 운영체제에도 함수(서브 루틴 혹은 프로시저)가 존재한다. 그리고 유저 영역처럼 스택도 존재한다. 만약에 존재하지 않았다면, 호출 시 전달되는 인자나 함수 내에서 선언한 지역 변수는 어디에도 할당할 수 없을 것이다. 또한, 코드 영역이나 전역변수 선언도 있다. 본질을 이해하는 것이 무척이나 중요하다.
02. B. 커널 모드와 유저 모드
Windows는 동작 시, 커널 모드와 유저 모드 중 한 가지 모드로 동작한다.
▶ 커널 레벨 쓰레드 모델, 유저 영역 쓰레드 모델
:메모리는 활용 대상에 따라, 유저 영역과 커널 영역으로 나뉘는데 유저 영역은 사용자가 구현한 프로그램 동작 시 사용하게 되는 메모리 영역이고, 커널 영역은 운영체제 동작 시 사용하게 되는 메모리 영역이다.
커널이 쓰레드를 지원할 경우 쓰레드 관리가 커널 영역에서 이뤄지기 때문에 커널 레벨 쓰레드 모델이라고 하고, 커널이 지원하지 않을 경우에 라이브러리를 통해 제공받아야 하는데 이러한 경우에는 유저 영역에서 쓰레드 관리가 이뤄지기 때문에 유저 레벨 쓰레드 모델이라고 한다.
커널 영역은 유저 영역에 비해서 상대적으로 중요하다. 유저 영역에서 메모리 참조 오류가 발생한다면 기껏해야 실행 중인 프로그램에만 영향을 미치게 되지만, 커널 영역은 커널의 코드가 실행되는 영역이므로 시스템 전체에 문제가 일어날 수 있다.
우리가 구현하는 프로그램은 유저 영역에서 실행되지만, C언어의 경우에는 메모리 참조가 용이하기 때문에 이에 대한 보장을 할 수 없다. 안전성 제공 측면에서 무언가 다른 방법이 필요한데, 이에 등장한 것이 커널 모드와 유저 모드다.
일반적인 프로그램은 커널 모드의 실행이 필요로 할 때, 커널 모드로의 전환이 일어난다. 타임 슬라이스가 지나서 스케줄러가 동작 시에 스케줄러는 커널의 일부에 해당하기 때문에 커널 모드로 전환된다.
커널 모드와 유저 모드의 차이점은 프로세스가 유저 모드에서 동작할 때, 커널 영역으로 접근이 금지된다는 것이다. 반면에 커널 모드에서 동작할 때에는 모든 영역의 접근이 허용된다.
▶ 주의해야 하는 점
: Windows에서 제공하는 일부 시스템 함수들은 호출 시, 커널의 구동을 필요로 한다. 이러한 것은 시스템에 부담을 주는 일이므로, 적절한 반영이 필요로 하다.
▶ 커널 모드와 유저 모드의 제공 대상
: 프로세서이다. Windows가 아니라, CPU에 달려있다는 것임을 명심하자.
'독서 > 뇌를 자극하는 윈도우즈 시스템 프로그래밍' 카테고리의 다른 글
| [스터디] 시스템 프로그래밍 - Chapter 13. 쓰레드 동기화 기법 1 (1) | 2023.11.08 |
|---|---|
| [스터디] 시스템 프로그래밍 - Chapter 12. 쓰레드의 생성과 소멸 (2) | 2023.11.01 |
| [스터디] 시스템 프로그래밍 - Chapter 10. 컴퓨터 구조에 대한 세 번째 이야기 (2) | 2023.10.25 |
| [스터디] 시스템 프로그래밍 - Chapter 9. 스케줄링 알고리즘과 우선순위 (2) | 2023.10.04 |
| [스터디] 시스템 프로그래밍 - Chapter 8. 프로세스간 통신(IPC) 2 (2) | 2023.10.04 |